
We are interested here in the first step of the parallelization of an OpenFoam simulation, which consists in using several cores on a single processor. For this purpose, OpenFoam does not use OpenMP (although dedicated to multi-core) but indeed MPI (as for the multi-processor parallelization of a cluster). A version of this study will follow with many more cores (and therefore a computer cluster). GPU parallelization is not considered here.
We will use a "turnkey" simulation of the OpenFoam distribution: aerodynamics of a motorcycle. Turbulence is modeled here using RANS (time average), in the SST version of the k-ω model. This modeling of turbulence can be performed with a sequential calculation in a reasonable time. The test case is presented there, but here are also some ParaView visualizations obtained by EIF-services:

And finally some animated sections of (i) longitudinal velocity, (ii) pressure and (iii) turbulent viscosity:
We are not concerned here with the physics of this numerical solution, but will only look at the computation time as it evolves with the number of cores used on the following machines:
- two local machines called HT8 (4 cores) and HT9 (2 cores) ; HT8 is equipped with an old-fashioned hard disk drive (HDD) but all the other machines in this study are equipped with SSD disks.
- EIF (2 cores): the server you are visiting right now!
- a cpu.c6i.4xlarge AWS instance with ad hoc AMI and CLI: 8 cores, with a total cost of less than 4 USD for this study.
The computation times with a single processor (simulation in sequential mode) are visualized by the following graph:
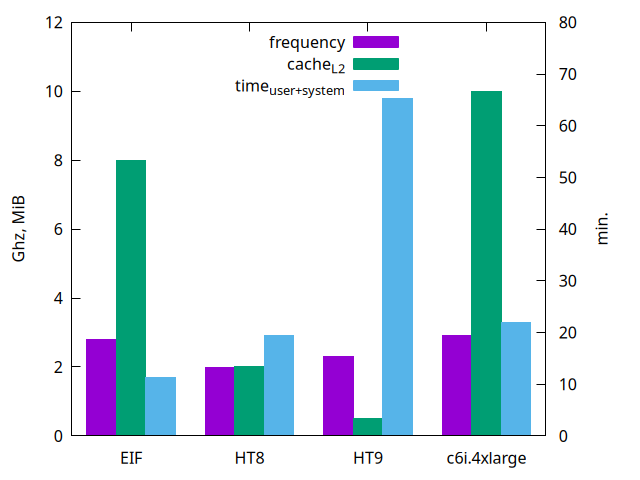
where one can see that HT9 is very slow. The processor speeds (in GHz) is quite comparable from one machine to another (limited by thermodynamics ;-) and the amount of cache memory largely explains the performance gaps.
We will not go further on this comparison because the main object of this study is the following strong scaling:
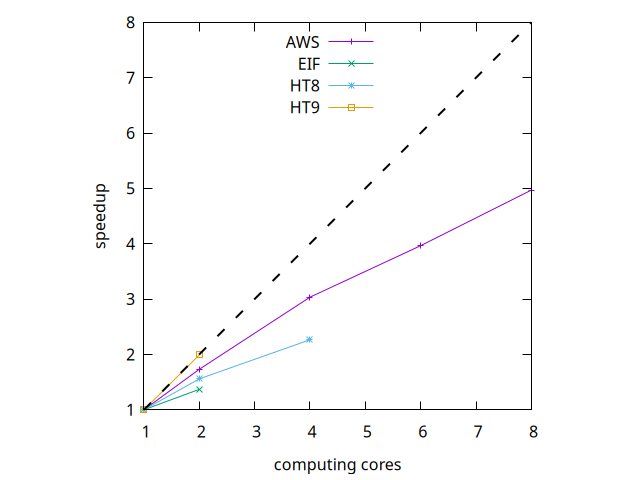
HT9 offers perfect scaling (!) and AWS performs better than the HT8 and EIF machines. The shortest calculation time is of course provided by the cpu.c6i.4xlarge instance with its 8 cores (2.3 minutes). The longest is HT8 running sequentially: 65.5 minutes.
N.B. The graphs have been completely automated thanks to the BAG (Bash, Awk, Gnuplot), which will allow easy completion of the multi-processor parallelization study (on AWS only).