
Nous nous intéressons ici à la première étape de la parallélisation d'une simulation OpenFoam, consistant à utiliser plusieurs cœurs sur un unique processeur. Pour cela OpenFoam n'utilise pas OpenMP (pourtant dédié au multi-coeurs) mais bien MPI (comme pour la parallélisation multi-processeurs d'une "ferme de calcul"). Une version de cette étude suivra avec beaucoup plus de cœurs (et donc une ferme de calcul). La parallélisation sur GPU n'est pas considérée ici.
Nous utiliserons une simulation "clé en main" de la distribution OpenFoam: aérodynamique d'une moto. La turbulence est ici modélisée par RANS (moyenne temporelle), dans la version SST du modèle k-ω. Cette modélisation de la turbulence est accessible au calcul séquentiel. Le cas-test est présenté là, mais voici aussi quelques visualisations ParaView obtenues par EIF-services:

Et enfin quelques sections animées de (i) la vitesse longitudinale, (ii) la pression et (iii) la viscosité turbulente:
Il ne s'agit pas ici de commenter la physique de cette solution numérique, mais seulement de regarder comment le temps de calcul évolue en fonction du nombres de cœurs utilisés sur les machines suivantes:
- deux machines locales baptisées HT8 (4 cœurs) et HT9 (2 cœurs) ; HT8 est dotée d'un disque dur à l'ancienne (HDD) alors que toutes les autres machines de cette étude sont dotées de disques SSD.
- EIF (2 coeurs): le serveur que vous visitez en ce moment!
- une instance cpu.c6i.4xlarge de AWS avec AMI et CLI ad hoc: 8 cœurs, avec un coût total inférieur à 4 USD pour cette étude.
Les temps de calcul avec un seul processeur (simulation en mode séquentiel) sont visualisés par le graphe suivant:
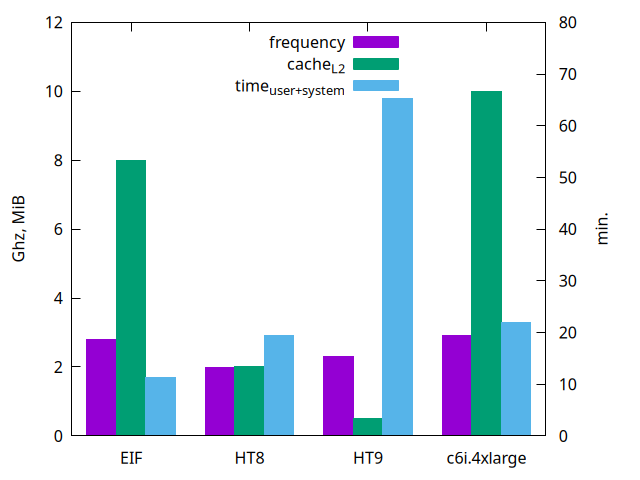
où l'on voit que HT9 est très lente. La vitesse des processeurs (en GHz) est assez comparable d'une machine à l'autre (limitée par la thermodynamique ;-) et la quantité de mémoire cache explique en grande partie les écarts de performance.
Nous n'irons pas plus loin sur ce comparatif car l'objet principal de cette étude est le strong scaling suivant:
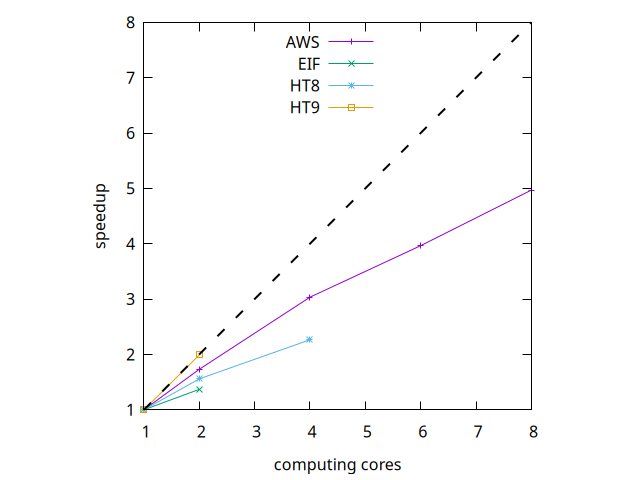
HT9 offre un scaling parfait (!) et AWS se comporte mieux que les machines HT8 et EIF. Le temps de calcul le plus court est bien entendu celui offert par l'instance cpu.c6i.4xlarge avec ses 8 cœurs (2,3 minutes). Le plus long est HT8 en séquentiel: 65,5 minutes.
N.B. Les graphiques ont été complètement automatisés grâce au BAG (Bash, Awk, Gnuplot), ce qui permettra de compléter facilement l'étude en parallélisation multi-processeurs (sur AWS uniquement).